Publications

[New] 3DFIRES: Few Image 3D REconstruction for Scenes with Hidden Surface
Linyi Jin, Nilesh Kulkarni, David Fouhey
CVPR 2024
abstract project page paper
This paper introduces 3DFIRES, a novel system for scene-level 3D reconstruction from posed images.
Designed to work with as few as one view, 3DFIRES reconstructs the complete geometry of unseen scenes, including hidden surfaces.
With multiple view inputs, our method produces full reconstruction within all camera frustums.
A key feature of our approach is the fusion of multi-view information at the feature level, enabling the production of coherent and comprehensive 3D reconstruction.
We train our system on non-watertight scans from large-scale real scene dataset.
We show it matches the efficacy of single-view reconstruction methods with only one input and surpasses existing techniques in both quantitative and qualitative measures for sparse-view 3D reconstruction.
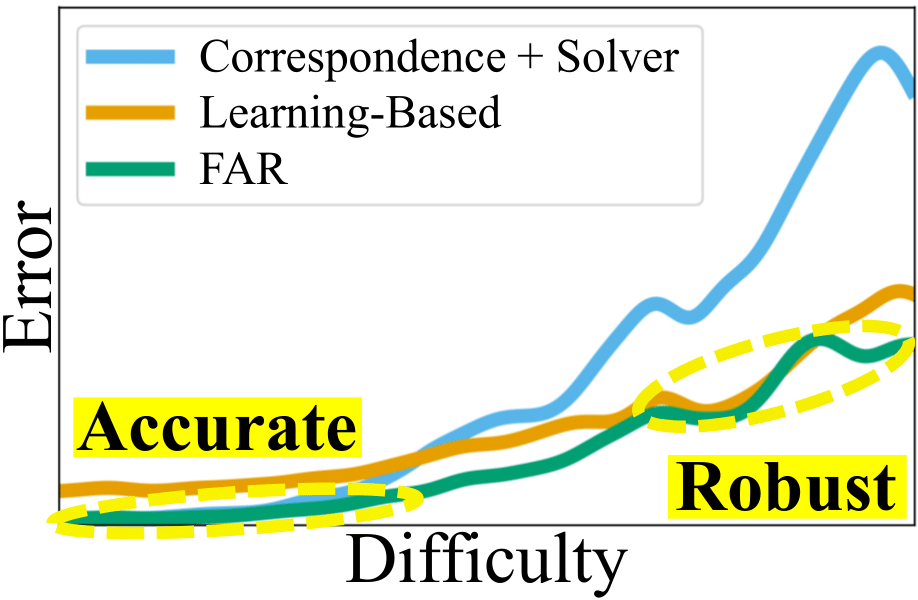
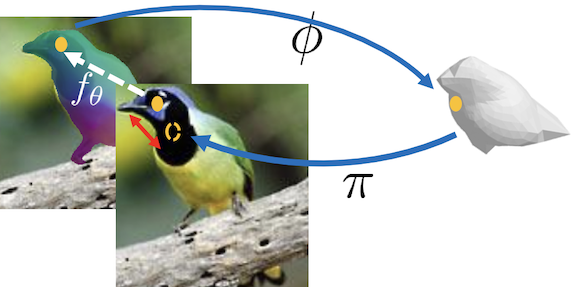
[New] FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation
Chris Rockwell, Nilesh Kulkarni, Linyi Jin, Jeong Joon Park, Justin Johnson, David Fouhey
CVPR 2024
abstract project page paper
Estimating relative camera poses between images has been a central problem in computer vision.
Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases.
Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and
can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the
best of both methods; our approach yields results that are both precise and robust,
while also accurately inferring translation scales.
At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations,
and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and
demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators,
showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-free Relocalization.
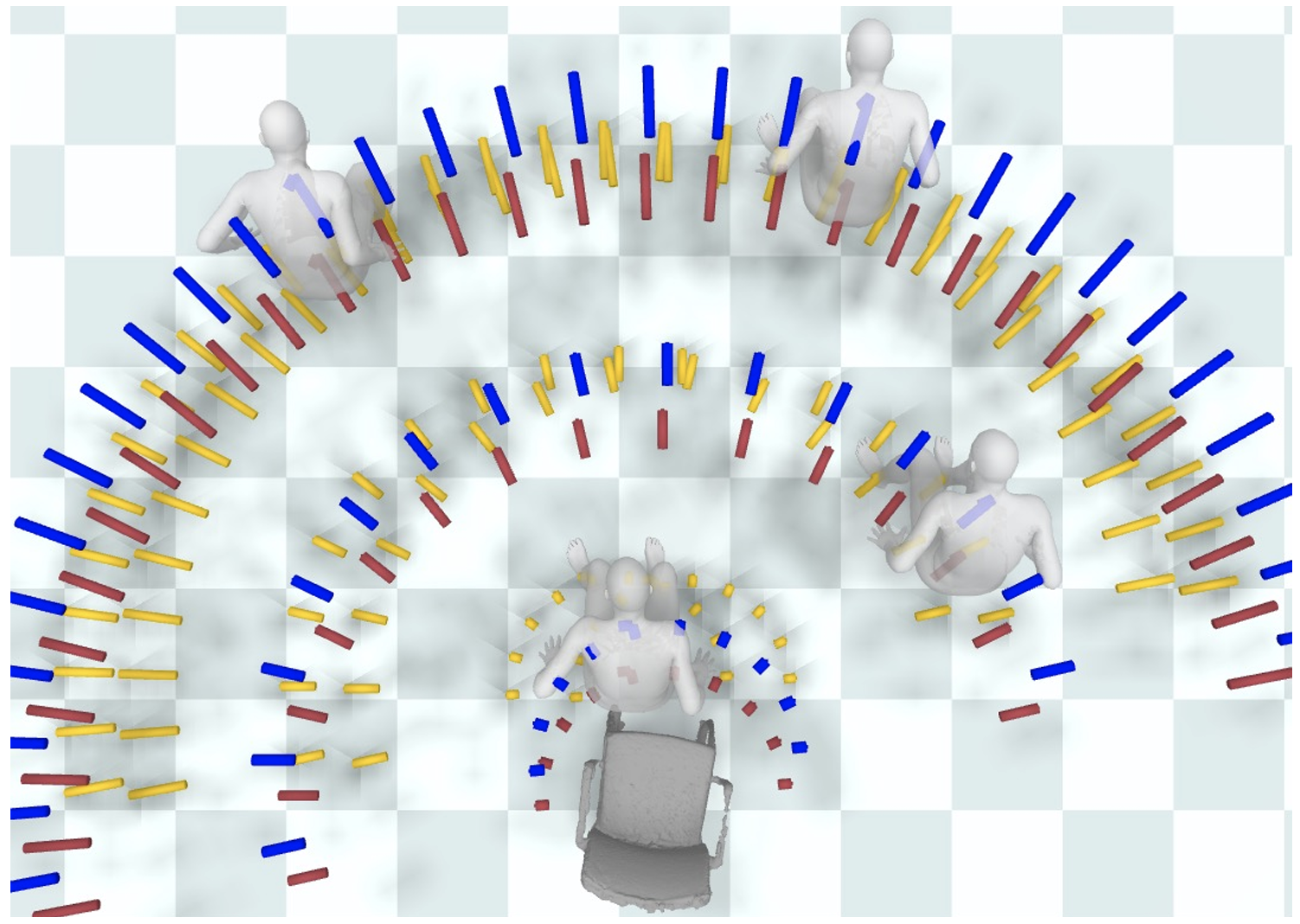
[New] NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
Nilesh Kulkarni, Davis Rempe, Kyle Genova, Abhijit Kundu, Justin Johnson, David Fouhey, Leonidas Guibas
CVPR, 2024
pdf abstract bibtex
project page

Learning to Predict Scene-Level Implicit 3D from Posed RGBD Data
Nilesh Kulkarni, Linyi Jin, Justin Johnson, David F. Fouhey
CVPR, 2023
pdf abstract bibtex
video project page

What's behind the couch? Directed Ray Distance Functions for 3D Scene Reconstruction
Nilesh Kulkarni, Justin Johnson, David F. Fouhey
ECCV, 2022
pdf abstract bibtex
video project page

Collision Replay: What does bumping into scenes tell you about scene geometry?
Alexandar Raistrick, Nilesh Kulkarni, David Fouhey
BMVC, 2021 ( Oral )
pdf abstract bibtex
video overview talk

Implicit Mesh Reconstruction from Unannotated Image Collections
Shubham Tulsiani, Nilesh Kulkarni, Abhinav Gupta
Arxiv, 2020
pdf abstract bibtex project page

3D-RelNet: Joint Object and Relational Network for 3D Prediction
Nilesh Kulkarni, Ishan Misra, Shubham Tulsiani, Abhinav Gupta
ICCV, 2019
pdf project page abstract bibtex code
On-Device Neural Language Model based Word Prediction
Seunghak Yu*, Nilesh Kulkarni*, Haejun Lee, Jihie Kim
COLING : System Demonstrations, 2018
pdf abstract bibtex
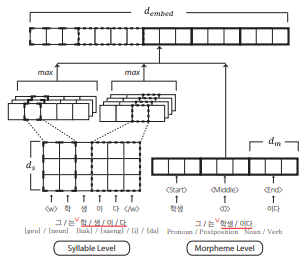
Syllable-level Neural Language Model for Agglutinative Language
Seunghak Yu*, Nilesh Kulkarni*, Haejun Lee, Jihie Kim
EMNLP workshop on Subword and Character level models in NLP (SCLeM), 2017
pdf abstract bibtex
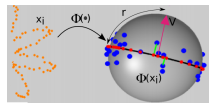
Robust kernel principal nested spheres
Suyash Awate*, Manik Dhar*, Nilesh Kulkarni*
ICPR, 2016
pdf abstract bibtex
Patents

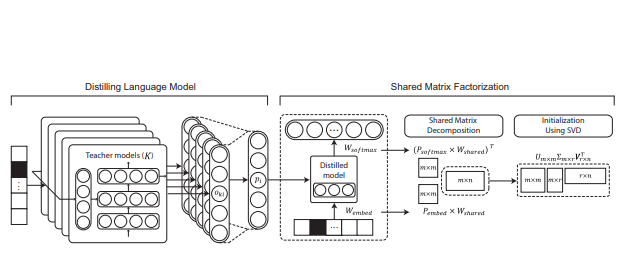
Electronic apparatus for compressing language model, electronic apparatus for
providing recommendation word and operation methods thereof
Seunghak Yu, Nilesh Kulkarni, Haejun Lee
US Patent App. 15/888,442
patent abstract
An electronic apparatus for compressing a language model is provided, the electronic
apparatus including a storage configured to store a language model which includes an embedding matrix
and a softmax matrix generated by a recurrent neural network (RNN) training based on basic data
including a plurality of sentences, and a processor configured to convert the embedding matrix into a
product of a first projection matrix and a shared matrix, the product of the first projection matrix and
the shared matrix having a same size as a size of the embedding matrix, and to convert a transposed
matrix of the softmax matrix into a product of a second projection matrix and the shared matrix, the
product of the second projection matrix and the shared matrix having a same size as a size of the
transposed matrix of the softmax matrix, and to update elements of the first projection matrix, the
second projection matrix and the shared matrix by performing the RNN training with respect to the first
projection matrix, the second projection matrix and the shared matrix based on the basic data.
Website inspired from here