|
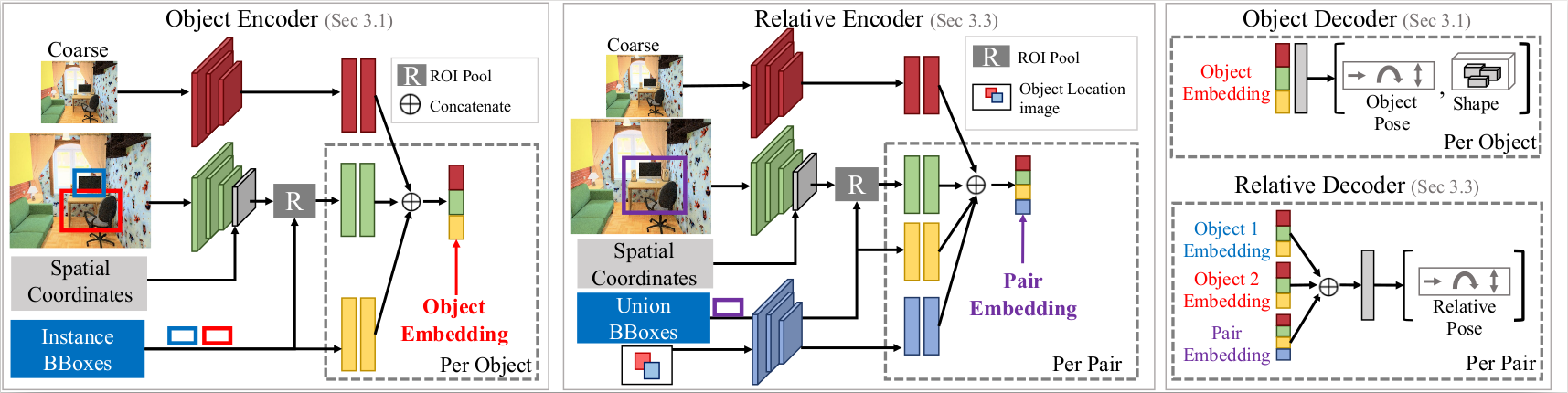
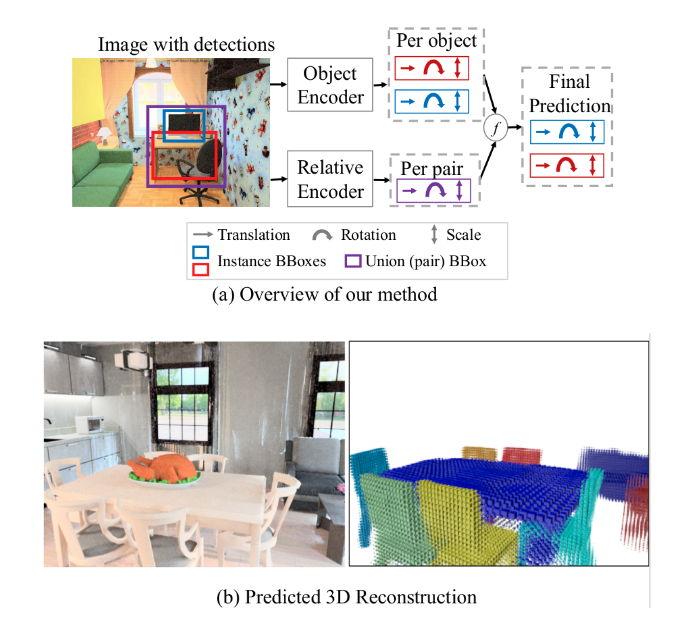
We study the problem of layout estimation in 3D by reasoning about relationships between objects. Given an image and object detection boxes, we first predict the 3D pose (translation, rotation, scale) of each object and the relative pose between each pair of objects. We combine these predictions and ensure consistent relationships between objects to predict the final 3D pose of each object. (b) Output: An example result of our method that takes as input the 2D image and generates the 3D layout.
|